Vue d’ensemble de mes projets
Voici un aperçu synthétique de mes principaux projets en data science, couvrant des domaines variés tels que la santé, les transports, la finance, l’immobilier et les systèmes de recommandation.
| Nom du projet | Type | Domaine |
|---|---|---|
| Prévision des ventes de magasins (Time Series Forecasting) | Régression temporelle | Grande distribution |
| Prédiction de la localisation des bus à Rio | Régression spatio-temporelle | Transports |
| Prédiction du risque d’obésité | Classification | Santé |
| Approbation de crédits bancaires | Classification | Finance |
| Estimation du prix de biens immobiliers | Régression multivariée | Immobilier |
| Système de recommandation de films | Clustering | Média / Recommandation |
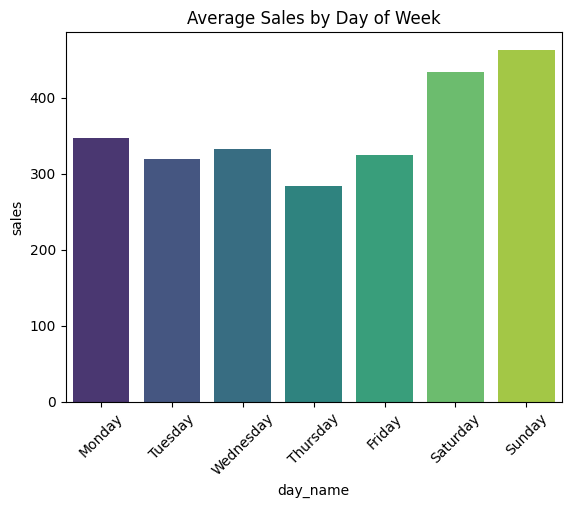
Prévision des ventes de magasins par séries temporelles (Time Series Forecasting)
L’objectif de ce projet était de construire un modèle capable de prédire précisement les ventes unitaires de milliers d’articles vendus dans différents magasins d'un grand distributeur alimentaire basé en Équateur (Corporación Favorita).
L’approche a consisté à intégrer plusieurs sources hétérogènes (ventes passées, caractéristiques des magasins et produits, cours du pétrole, jours fériés, événements exceptionnels, jours de paie) afin d’enrichir un modèle de séries temporelles. Après un important travail de feature engineering (imputation par régression, croisement géographique des jours fériés, etc.), le modèle a atteint une performance solide sur les deux semaines de prévision cible.
Données
- Données principales : séries temporelles de ventes par magasin et famille de produits, incluant les promotions (entre janvier 2013 et juillet 2017).
- Données complémentaires : métadonnées des magasins (ville, type, cluster), prix du pétrole brut, jours fériés et événements spéciaux, nombre de transactions par magasin et par jour.
- Contexte économique : salaires publics versés deux fois par mois (le 15 et le dernier jour) et impact d’un séisme majeur sur les ventes en avril 2016.
Étapes principales
- Chargement des données et concaténation des dataframes
- Enrichissement contextuel (feature engineering)
- Analyse exploratoire des données (EDA)
- Imputation des valeurs manquantes
- Entrainement des premiers modèles
- LightGBM : RMSLE = 0.5674
- RandomForestRegressor : RMSLE = 0.4956 (plus performant)
- Ajout des informations de jours fériés → RF RMSLE = 0.4931
- Ajout du prix du pétrole :
- 28.52% de données manquantes
- Imputation des valeurs manquantes par interpolation
- RF RMSLE = 0.4737
- Ajout de l'information des paiements (tous les 15 jours) → RF RMSLE = 0.4722
-
Modèle retenu : RandomForest
Méthode d'évaluation : RMSLE
Score : 0.4722
Prédiction de la localisation des bus à Rio
L’objectif de ce projet est de nettoyer et structurer une base de données fortement bruitée, dans le but d’entraîner un modèle capable de prédire la localisation des bus à partir d’un historique de positions GPS. Deux tâches de prévision sont abordées :
- Prédire le moment d’arrivée d’un bus à un lieu donné, à partir d’une série historique de positions GPS horodatées.
- Estimer la position d’un bus à partir d’un horodatage spécifique.
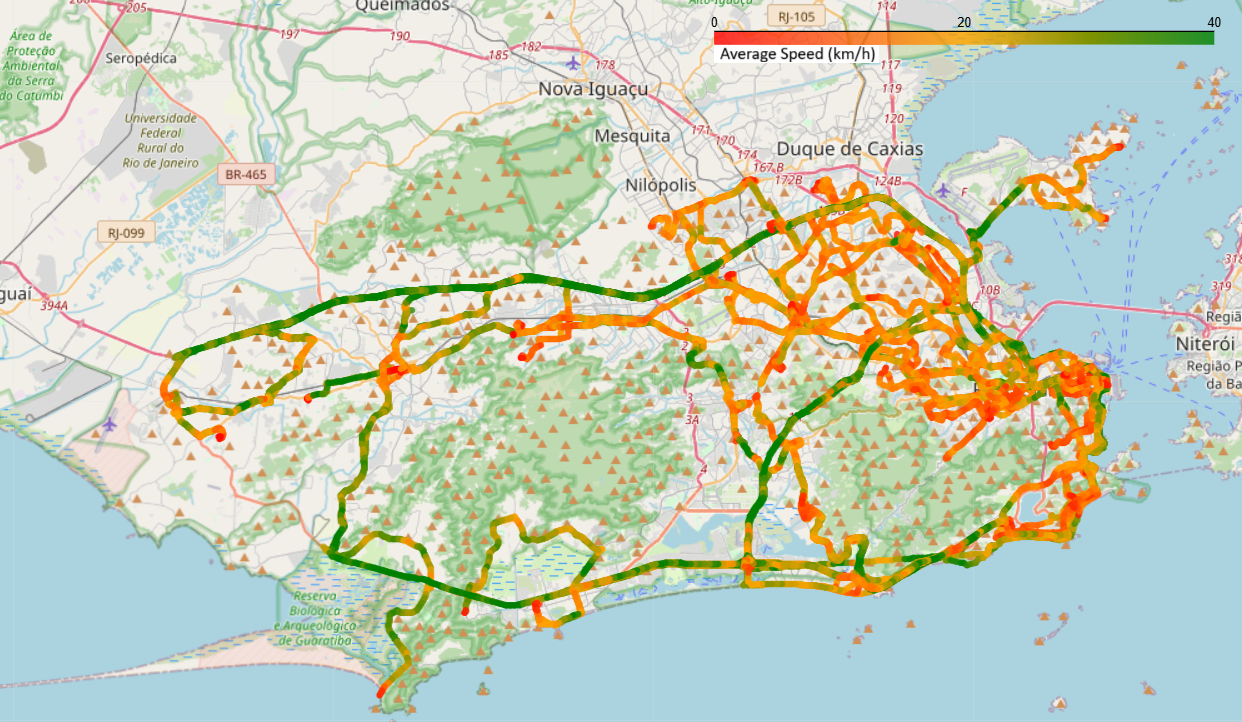
Dans ce projet, j’ai conçu un pipeline complet de traitement et d’analyse de données GPS brutes (plus de 50 Go). Les données, très bruitées et souvent incohérentes (positions erronées, GPS actifs en dépôt, horaires incorrects), ont été nettoyées, filtrées et structurées dans une base PostgreSQL. J’ai identifié les trajets réels, les terminaux, les dépôts, et attribué dynamiquement le sens de circulation à chaque véhicule. À partir de cette base fiable, j’ai segmenté les trajets en tronçons homogènes et calculé les vitesses moyennes pour modéliser les conditions de circulation. L’ensemble du travail a permis de poser les fondations d’un modèle de prédiction spatio-temporelle capable d’estimer la position d’un bus à un instant donné ou son temps d’arrivée à un arrêt. Ce projet a permis de combiner data engineering, analyse géospatiale et machine learning dans un contexte réel à grande échelle.
Données
Les données exploitées dans ce projet proviennent de capteurs GPS embarqués dans les bus de Rio de Janeiro. Chaque enregistrement représente une position géographique à un instant donné, enrichie de plusieurs métadonnées. Voici les principales variables disponibles (les noms des variables sont en portugais):
- ordem : identifiant unique du véhicule, permettant de suivre chaque bus individuellement.
- latitude / longitude : coordonnées GPS du bus, exprimées en degrés décimaux.
- datahora : horodatage du point GPS (timestamp en millisecondes), correspondant à l’heure de capture du signal.
- velocidade : vitesse instantanée du bus en km/h.
- linha : numéro de la ligne de bus empruntée (ex. 483).
- datahoraenvio : heure à laquelle le signal GPS a été envoyé au serveur.
- datahoraservidor : heure d’enregistrement du signal par le serveur (considérée comme la plus fiable pour les analyses temporelles).
Au total, plus de 50Go de données allant du 25 avril au 10 mai 2024 (16 jours de données)
Étapes principales
- Importation des données dans une base PostgreSQL
- Nettoyage et structuration :
- Suppression des points incohérents (hors de Rio, avec des vitesses trop élevées ou négatives…)
- Conversion des timestamps et des colonnes latitude/longitude en points GPS
- Analyse exploratoire des données GPS (EDA)
- Identification des dépôts où stationnent les bus la nuit :
- Par temps d’arrêt longs en dehors des heures de circulation
- Identification des trajets de chaque ligne :
- Interpolation pour recréer une densité de points dans les zones à circulation rapide. La période d’émission des données étant fixe, lorsque le bus roule plus vite, les points GPS sont plus espacés.
- Identification des terminaux de toutes les lignes :
- Par temps d’arrêt longs et répétés dans une journée, qui ne correspondent pas à des dépôts
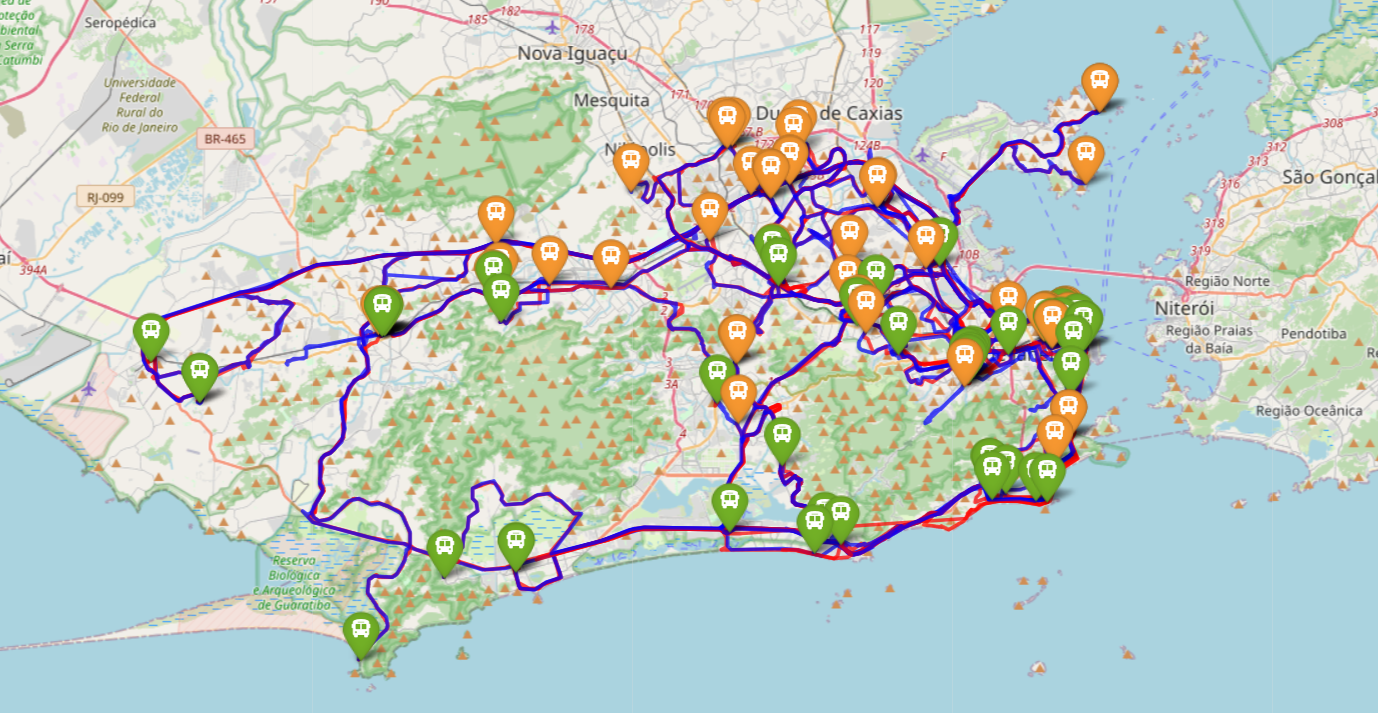
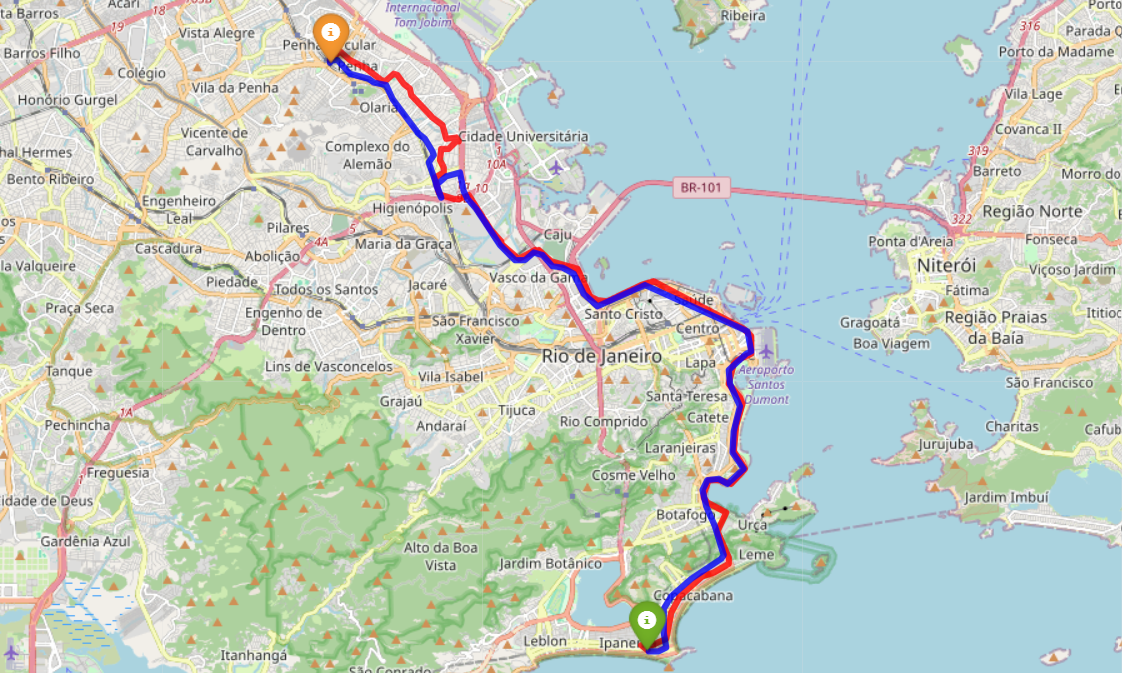
- Attribution du sens de circulation (aller/retour) à chaque point GPS d’une ligne :
- Voir les trajets bleus/rouges sur l’image (ligne 483)
- Modélisation de la vitesse moyenne sur les tronçons partagés :
- Découpage en tronçons homogènes (environ 250 m) de l’ensemble des routes parcourues par au moins une ligne de bus
- Calcul des vitesses moyennes par tronçon (voir la dernière image)
- Création de features à partir des données structurées et du modèle de vitesse pour préparer l'entrainement d'un modèle
-
Construction d'une base de données SQL
Données nettoyées et prête pour l'entrainement d'un modèle
Données traitées : 50 Go

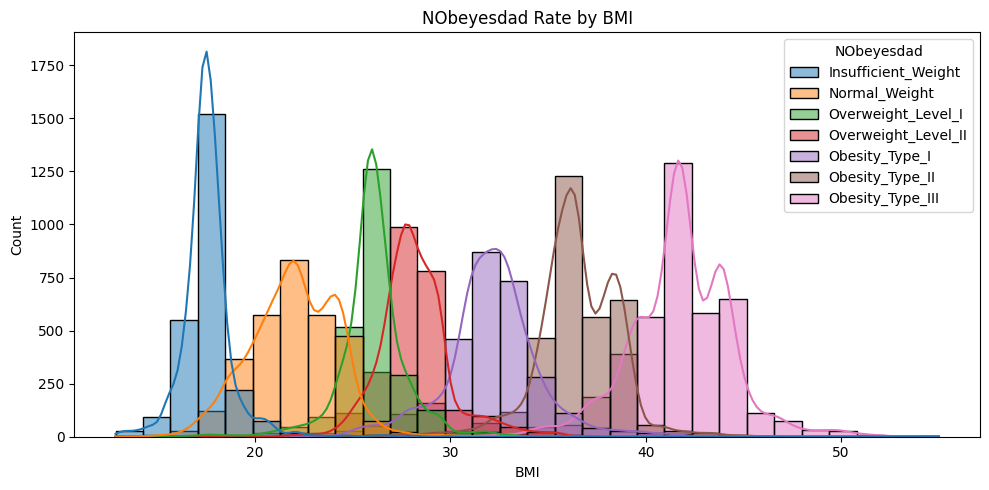
Prédiction du risque d’obésité pour prévenir les maladies cardiovasculaires
Projet de classification visant à prédire le risque d’obésité à partir de données de santé et de mode de vie. Ce risque est fortement corrélé aux maladies cardiovasculaires, ce qui rend la prédiction pertinente sur le plan médical et préventif.
Après un travail de feature engineering (notamment la création de l’IMC), plusieurs modèles ont été testés et comparés. L’algorithme XGBoost optimisé s’est imposé comme le plus performant, atteignant une précision de 91,26 %.
Données
- Variables personnelles : âge, sexe, taille, poids, antécédents familiaux d’obésité
- Habitudes alimentaires : consommation d'aliments riches en calories (FAVC), consommation d’eau (CH2O), consommation de légumes (FCVC), nombre de repas par jour (NCP), consommation d'alcool (CALC), grignotage entre les repas (CAEC)
- Habitudes de vie : tabagisme, suivi de la consommation calorique (SCC), fréquence d'activité physique (FAF), temps passé devant les écrans (TUE), moyens de transport utilisés
Étapes principales
- Prétraitement des données :
- Nettoyage des valeurs manquantes
- Encodage des variables catégorielles
- Normalisation des variables numériques
- Feature engineering :
- Création de l’IMC à partir du poids et de la taille
- Analyse de l’importance des variables
- Modélisation :
- Comparaison de Random Forest, SVM et XGBoost
- Optimisation des hyperparamètres avec GridSearchCV
-
Modèle retenu : XGBoost
Méthode d'évaluation : Accuracy
Score : 91.26 %
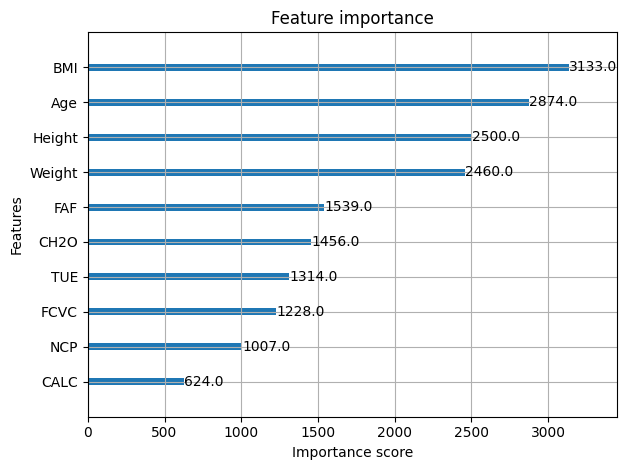
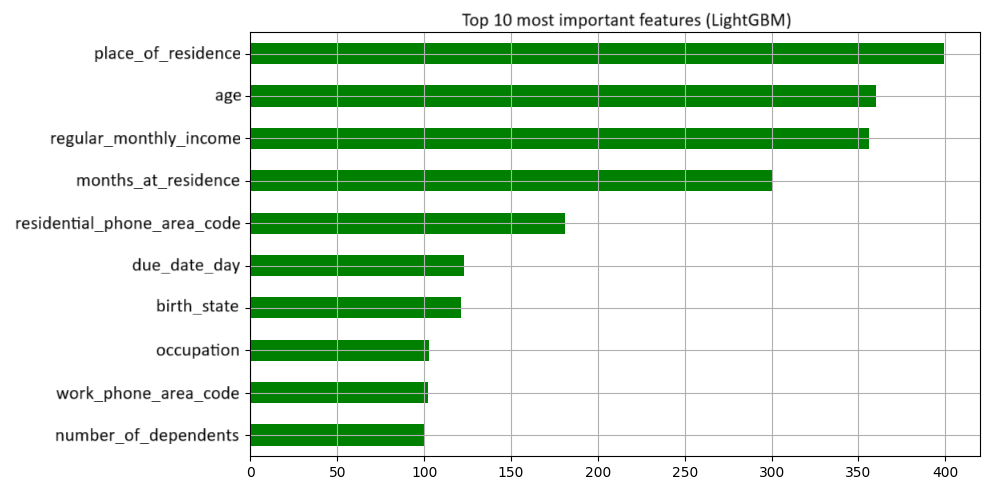
Classification pour l’approbation de crédits bancaires
Projet de classification visant à prédire la capacité de remboursement d’un crédit bancaire à partir des informations personnelles, professionnelles et financières des demandeurs. Après un travail de préparation des données (nettoyage, imputation, encodage) et l’entraînement de plusieurs modèles, l’algorithme LightGBM optimisé par RandomizedSearchCV a obtenu les meilleures performances.
Ce projet m’a permis de mettre en œuvre un pipeline complet de machine learning, depuis l’analyse exploratoire jusqu’à l’optimisation fine des hyperparamètres, en passant par le traitement des valeurs manquantes et la sélection des variables les plus influentes.
Données
- Variables personnelles : âge, sexe, situation familiale, nombre de dépendants
- Variables professionnelles : métier, ancienneté, statut de propriétaire, type de résidence
- Informations financières : revenus réguliers et supplémentaires, patrimoine personnel, nombre de comptes bancaires
- Comportements bancaires : possession de cartes, téléphone, email, statut de travail
- Cible : statut d’inadmissibilité au crédit (variable inadimplente)
Étapes principales
- Importation des bibliothèques et des données
- Analyse exploratoire des données (EDA)
- Prétraitement :
- Imputation des valeurs manquantes
- Encodage des variables catégorielles
- Normalisation des variables numériques
- Modélisation :
- Tests de Random Forest (0,5782), XGBoost (0,5896), LightGBM (0,5964)
- Validation croisée (accuracy)
- Calcul de l’importance des variables avec LGBMClassifier
- Optimisation :
- Recherche d’hyperparamètres avec RandomizedSearchCV
- Amélioration du score final avec LightGBM : Accuracy = 0.5996
-
Modèle retenu : LightGBM
Méthode d'évaluation : Accuracy
Score : 0.5996

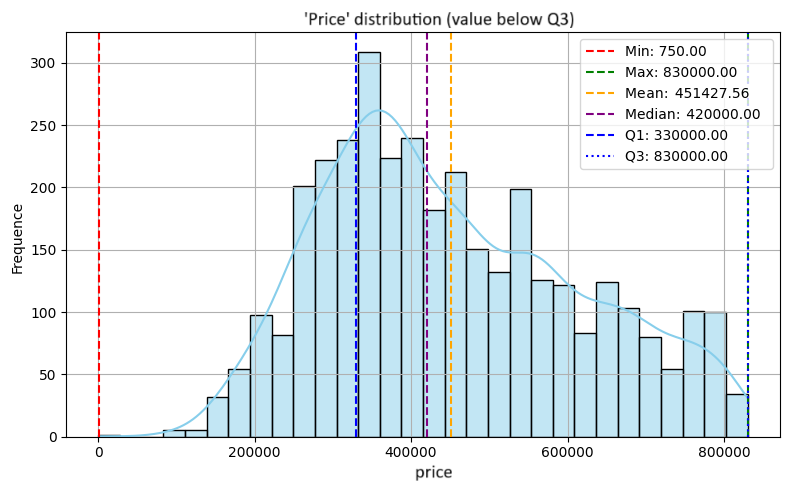
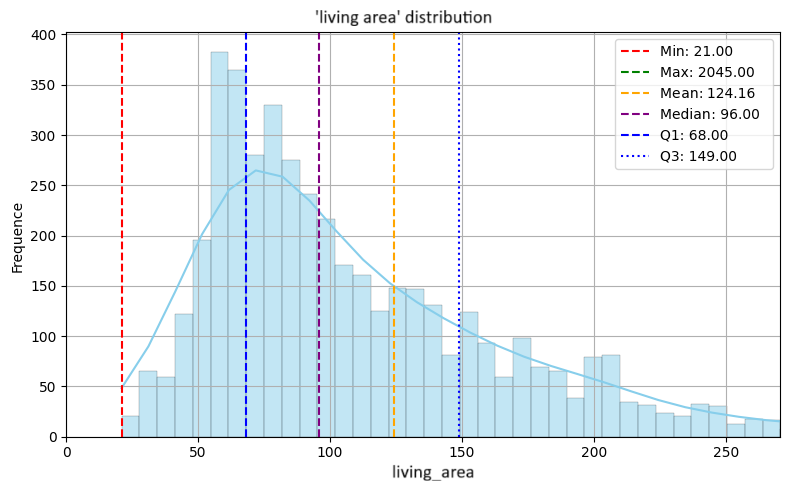
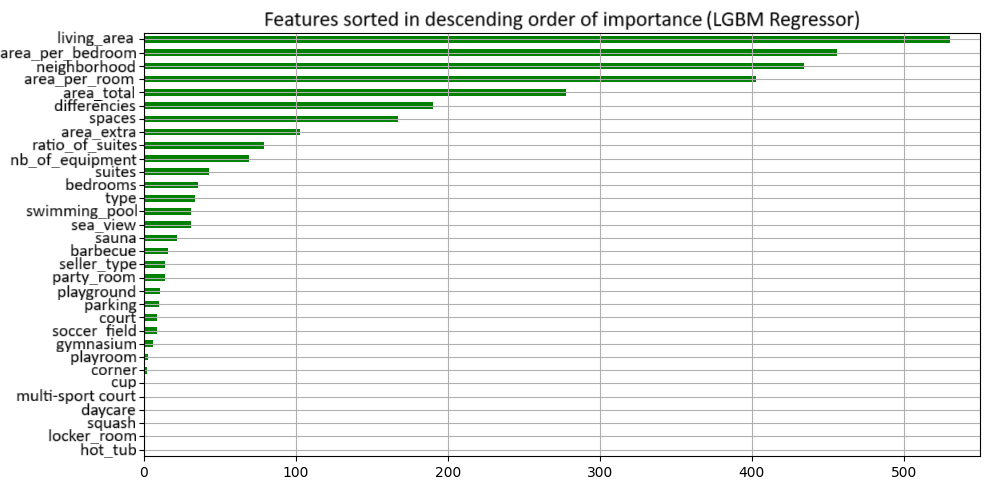
Régression multivariée pour l’estimation du prix de biens immobiliers
L'objectif de ce projet de régression était d'estimer le prix de biens immobiliers à partir de caractéristiques structurelles (type de bien, surface, nombre de pièces, localisation) et d’éléments différenciants (piscine, salle de sport, vue sur mer, etc.). L’accent a été mis sur la gestion des valeurs extrêmes (méthode de Tukey) et l’extraction de mots-clés à partir d’une variable textuelle.
Données
- Type de bien : appartement, maison, loft, studio
- Localisation : quartier de résidence
- Caractéristiques : nombre de chambres, nombre de places de stationnement, surface habitable, surface extérieure
- Éléments différenciants : piscine, sauna, salle de sport, terrain de sport, salon de jeux, vue sur mer, etc.
- Variable cible : prix du bien immobilier
Étapes principales
- Prétraitement :
- Détection et traitement des outliers via la méthode de
Tukey :
- Calcul des quartiles Q1 et Q3, puis de l’intervalle interquartile (IQR = Q3 - Q1)
- Conservation uniquement des valeurs comprises entre Q1 - 1.5 x IQR et Q3 + 1.5 x IQR
- Permet d’atténuer l’impact des biens atypiques (ex. villas de luxe) ou des erreurs de saisie sur la variable cible “prix”
- Détection et traitement des outliers via la méthode de
Tukey :
- Feature engineering :
- Encodage des variables catégorielles
- Normalisation des variables numériques
- Extraction de mots-clés à partir de la variable textuelle “Points en plus”
- Transformation en variables indicatrices
- Modélisation :
- Tests de Random Forest, XGBoost, LightGBM
- Validation croisée (RMSPE)
- Importance des variables calculée avec LGBMClassifier
- Optimisation :
- Recherche d’hyperparamètres avec Optuna
-
Modèle retenu : LGBMRegressor
Méthode d'évaluation : RMSPE
Score : 0.2527
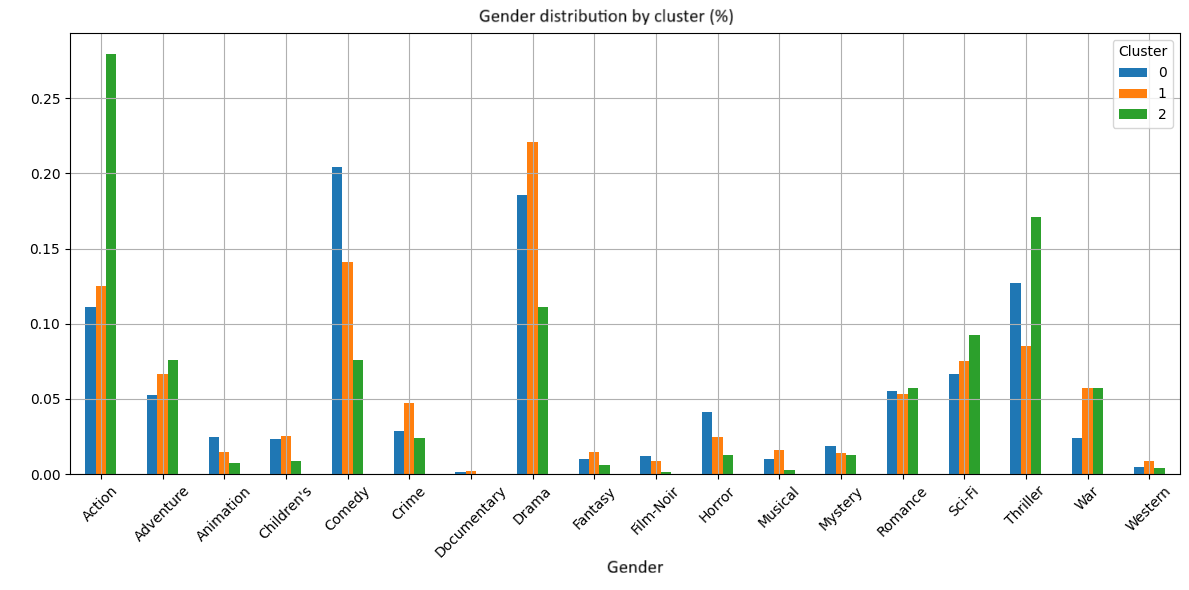
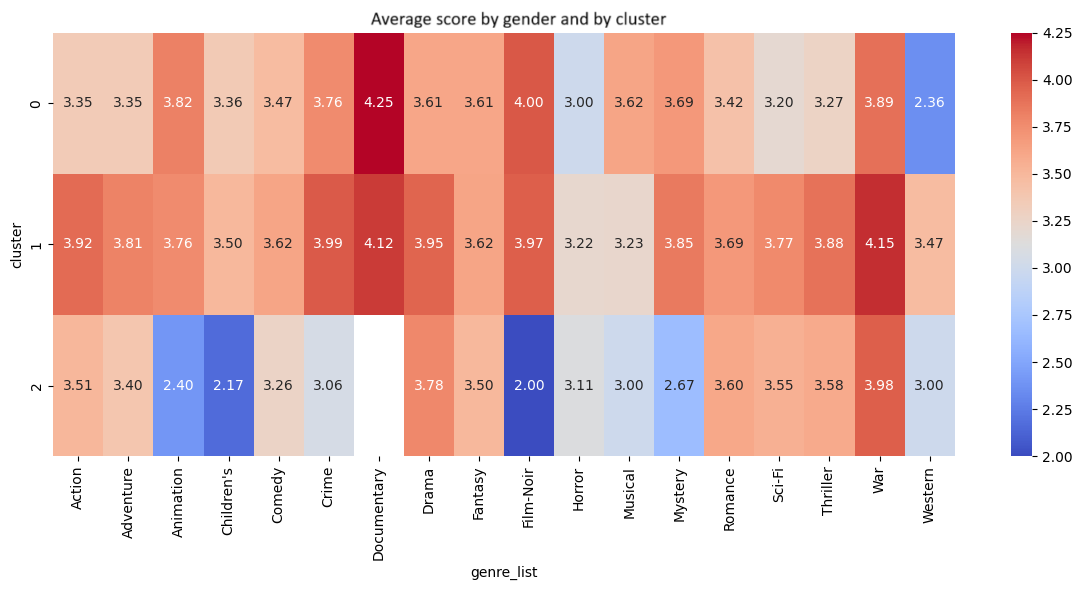
Système de recommandation de films avec MovieLens1M
Projet de clustering réalisé sur la base MovieLens1M (plus d’un million de notes de films). L’objectif était d’identifier des groupes d’utilisateurs et de films à partir de leurs caractéristiques (genres, notes attribuées, réalisateurs, acteurs principaux) afin de concevoir un système de recommandation.
Des techniques de réduction de dimensionnalité (PCA, SVD) et des algorithmes de clustering (K-Means, DBSCAN, Agglomerative Clustering) ont été utilisés pour explorer les structures latentes dans les données et construire un prototype de recommandation basé sur les similarités.
Données
- Genres cinématographiques : action, comédie, drame, etc.
- Réalisateurs et acteurs principaux
- Notes attribuées par les utilisateurs
- Profil des utilisateurs : âge, sexe, profession
Étapes principales
- Prétraitement des données :
- Nettoyage et transformation des données brutes
- Encodage des variables catégorielles (genres, professions, etc.)
- Normalisation des notes pour corriger les biais de notation
- Réduction de dimensionnalité :
- Application de la PCA pour conserver l’essentiel de la variance
- Application de la SVD pour révéler les structures latentes dans la matrice utilisateur-film
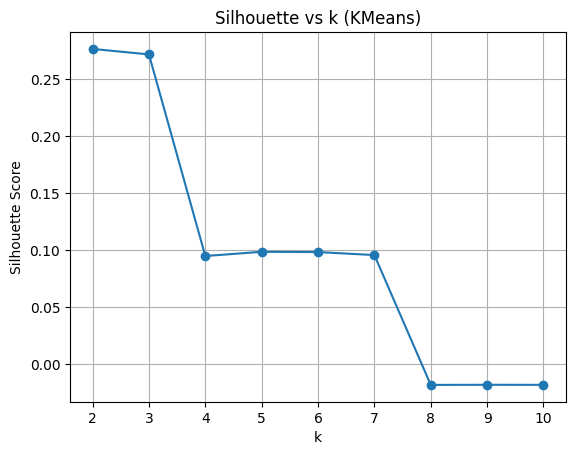
- Clustering :
- Tests de K-Means, DBSCAN, Agglomerative Clustering
- Évaluation via des métriques non supervisées (silhouette score)
- Sélection des clusters les plus interprétables
- Analyse des clusters :
- Interprétation des groupes formés (ex. films d’action à gros budget, comédies romantiques, etc.)
- Identification de profils d’utilisateurs types selon leurs préférences
- Système de recommandation basé sur l’appartenance à un cluster
-
Méthode : Clustering non supervisé
Techniques : PCA, SVD, K-Means, DBSCAN
Base : MovieLens1M (1M+ notes)